2025
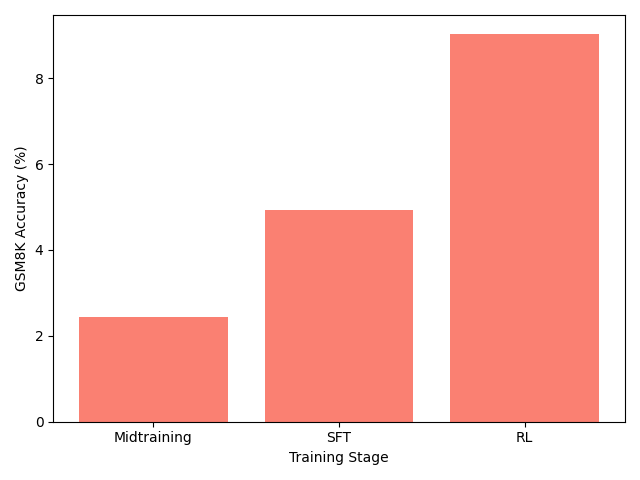
Nanochat
I trained my own LLMs from Karpathy’s repo.
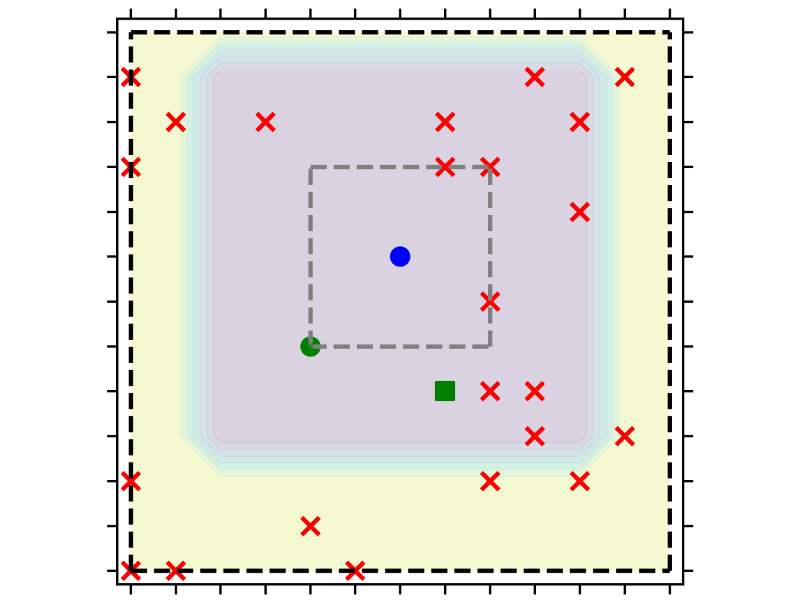
Probing Bacterial Parasitism Using Multi-Agent Reinforcement Learning
Bacteria in their natural environment do not exist in isolation but with several other species. Much richer dynamics can be observed with additional species, such as commensalism and parasitism, which cannot be observed with a single species. In this work, we used multi-agent reinforcement learning to find the optimal policies of these bacterial agents in different environments. In particular, we try to quantify and understand the optimal level of antagonism for a given environment.
2020
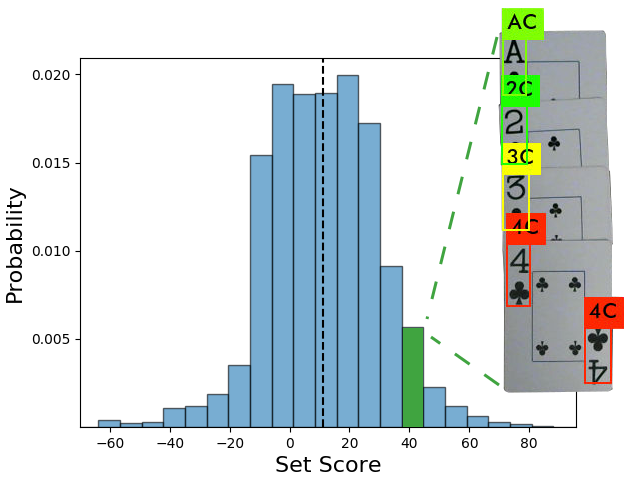
Lost Cities Part 2: Learning from Deep Q-Networks
Now that we developed a deep Q-network that achieved a mean score of 45 points in Lost Cities, what can we learn from it? We probe this network to understand the high-level strategy choices it makes, and we quantify the distributions of important metrics governing its strategy. To better evaluate its performance, we want to play against the network ourselves. Can we train an object detection architecture so that we can play against the deep Q-network using a game with physical cards?
Lost Cities: Using Deep Q-Networks to Learn a Simple Card Game
Lost Cities is a simple two-player card game that is not unlike competitive solitaire. Players are forced to invest in playing cards while lacking crucial information about future cards that may be drawn. To determine optimal play, I developed and trained a deep Q-network that learned to maximize its collected score through self-play. How well can a simple neural network perform with so much information unknown?